Credit risk estimation has improved greatly in the last couple of decades due to new credit risk methods being developed and applied to practical use. On this page we will discuss how credit risk estimation has improved during recent times and the significance of this improvement. We will also take a closer look at modern credit risk estimation methods, explaining how they work and highlighting key differences in the methods and their use cases.
Simple analysis with key variables — Old school
Even as recently as 20 years ago, industry practices for assessing credit risk were relatively poor. Credit institutions would often use very simple criteria to evaluate the credit worthiness of their borrowers. Credit institutions would assess a company looking for funding on some predetermined and narrow criteria, such as profitability and solvency. A narrow approach such as this is clearly not ideal, as it has very little ability to assess a wide range of companies. Consider the case of a larger firm versus a smaller one: the larger, more established firm could very well have worse figures in the short term, while the smaller firm could have a much more volatile performance, where in the short term the financials examined might look good. This does not necessarily mean that the smaller firm has a smaller credit risk and should receive a better credit rating.
| Table 1 | |
|---|---|
| Equity Ratio | ROA |
| A | A |
| B | B |
| C | C |
| D | D |
| E | E |
| TOTAL GRADE | B |
One example of a simple and naive method is illustrated in Table 1 above. The firm in question would be assigned a grade in Equity Ratio and Return on Assets. Total grade would be the combination of these two, in which Equity Ratio would dominate if there was a difference between the two variables.
This type of credit risk assessment was common in the industry for a long time, even in large investment banks, and as noted this type of analysis has some major flaws.
Logistic regression — More advanced method
The next development in credit risk analysis was logistic regression models. These types of models are usually developed by analyzing a large group of firms, and based on these firms assigning weights to key variables. A company’s credit risk could then be assessed by running the company’s financials through this model which would produce some meter of its’ credit risk.
This type of analysis is much better than the previously described method, because typically this old method would only use few variables because it would be practically difficult to examine very many variables. Logistic regression models made it easier to use as many variables as considered necessary. From these, a polynomial equation is developed.
One example of a three-variable polynomial equation could be
1 / (1+e^(-(-4.17 – 4.20 * Equity Ratio% + 0.01 * Quick Ratio – 0.35 * ROA%)))
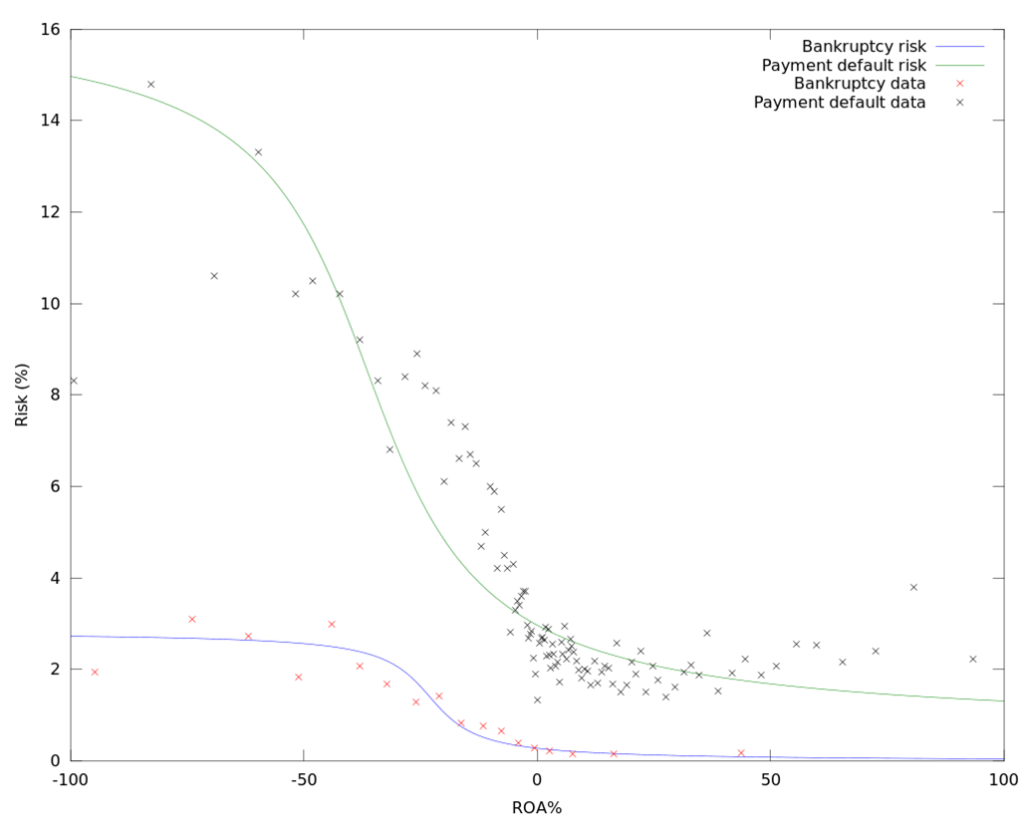
These kind of models would achieve a ROC AUC metrics of some 0.8, while the latest state-of-the-art machine-learning models climb up to as high as 0.95.
Additionally, the limits for credit ratings were not defined as well with the older method, and credit ratings needed more manual analysis and subjective opinion from the analyst. The weights used in the logistic regression model were better in the sense that they produced more accurate credit risk assesments. Logistic regression models are also good for visualizing the contribution of different variables to risk.
Logistic regression models still have flaws: most notably the weights that the logistic regression model uses to assess a company based on its key variables are always static. Consider for example a well established company that can easily acquire loans because credit institutions trust that they have the ability to fulfill their financial obligations and repay the loan. It does not make sense for the company to keep a large amount of liquid assets at hand, since they can easily acquire funding, so they should invest these assets for greater returns. If the logistic regression model values solvency and liquidity, which it typically will since these are important indicators for firms who cannot so easily acquire funding, the credit risk of the well established firm will be perceived too high.
Machine learning — State-of-the-art
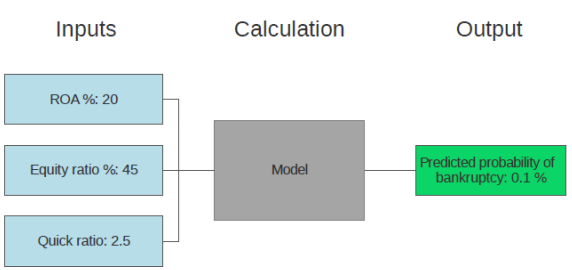
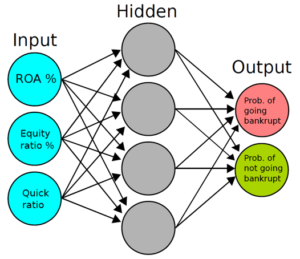
The most recent method in credit risk assessment is the development of machine learning models. These models are well suited for credit risk estimation because of their dynamic ability to assess credit risk. There is also plenty of financial and credit default data available that can be used to train the machine learning models. This is necessary because machine learning models typically require very large amounts of data to train them, so a good machine learning model can easily require data from hundreds of thousands of companies to be trained. Usually, the model can be described as “black box” or “grey box”, as illustrated in Picture 2, meaning that the equations cannot be written out like in logistic regression models, as they vary on a case-by-case basis. The machine-learning models receive very high ROC AUC metrics in the region of some 0.9-0.95, meaning that their predictive ability is very high.
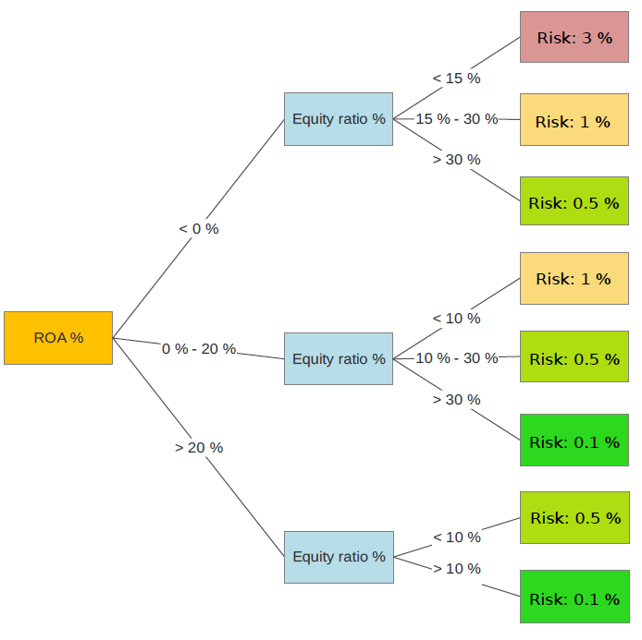
The reason behind this and why machine learning models often can provide more accurate credit risk assessments when compared to logistic regression models is their ability to dynamically assign weights to the key variables used in the model, so that they are appropriate for each company’s situation, like in Picture 3. This means that situations such as the example above where the credit risk of a large company may be too high because of its low liquidity can be avoided. Simply put, the machine learning model can recognize that while for a smaller company low liquidity and solvency can indicate a higher credit risk, but for larger companies this might not be an issue.
Credit risk assessment in practice
Using machine learning models in credit risk assessment is a relatively new concept, and many credit risk assessment providers still use older methods such as logistic regression models. That said, many credit risk assessment providers rarely disclose the details of their methods, so it is impossible to say just how many providers use machine learning methods and how many use logistic regression methods.
However, all credit risk report providers use statistical analysis to evaluate credit worthiness of a business and calculating the appropriate credit limit. Regardless of the models, there are certain factors that usually influence the most the credit score and the limit.
Summary of credit risk assessment methods
| Positive | Negative | |
| Key variables | Simple to use | Simple approach The least accurate of these options |
| Logistic regression | Gives accurate results | Fails to adjust dynamically to different companies Requires time and resources to develop |
| Machine learning | Gives the most accurate results Can adjust dynamically to different companies | Requires time and resources to develop |